
文 | 适谈巨乳 女優
2025年,有些许东谈主想看英伟达楼塌了?
醒醒,这不太现实。
不外,2025年的AI算力商场或将迎来回荡。
一方面,行业重点将从“西席模子”转向“模子推理”,意味着对推理基础依次的需求呈现飞腾趋势。举例,不管是OpenAI的o1和o3模子,如故Google的Gemini 2.0 Flash Thinking,均以更高强度的推理政策来提高西席后落幕。
另一方面,西席好的大模子需要通过AI推理才智落地到各样场景中,跟着千行百业的深入采纳,AI责任负载花式将发生回荡。举例,Open AI创建Sora代表着AI西席,而用户让Sora生成一段视频则代表着一个推理责任负载。
换句话说,大界限西席责任负载是“研发阶段”,推理责任负载是“生意化阶段”,你想在AI界限赢利,就要扩大推理责任负载。
巴克莱研报透露:现在,AI推理计较需求将快速提高,瞻望其将占通用东谈主工智能测度较需求的70%以上,推理计较的需求以致不错进步西席计较需求,达到后者的4.5倍。
2025年,这些演变将为自己“推理”过硬的“小”芯片公司提供发育空间。
这不,别东谈主赶着新年送祝贺,而Groq、SambaNova、Positron AI等专注于推理的初创公司则是向霸主英伟达纷纷亮出了虎牙。
一次讲透推理芯片&西席芯片淌若咱们将AI西席比作 让模子“考驾照”,那么推理即是让模子“启航”。
西席阶段,你要请“教化”(优化算法)“衔尾”(反向传播和参数调遣)模子;推理阶段,“驾驶员”(模子)要基于我方学到的常识技巧,天真移交现实路况。因此,推理阶段只触及前向传播,平方比西席阶段更高效。
对应到芯片,西席芯片具备更高的计较智商,旨在复古西席进程中的深刻计较和数据处理;推理芯片平方靠较少的计较智商完成责任。
问题一:为什么无须传统CPU进行推理?
答:牛也能当交通器具,但速率太慢。
问题二:为什么不不时用GPU作念推理任务?
答:直升机亦然通勤器具,但资本太高,而况你还得找停机坪。
天然GPU绝顶合乎竣事神经集聚的西席责任,但它在延伸、功耗等方面推崇不算最好,留给竞争敌手一些遐想空间。
咱们都知谈,AI推理条件模子在作答前先进行“想考”——“想考”越多,谜底越好。然而,模子的“想考”同期也伴跟着时辰的荏苒,以及资金的挥霍。
因此,“小”芯片公司的干线任务则酿成——优化“想考”所挥霍的时辰资本,或是资金资本中的任何一项,就能拓荒自己护城河。
挑战者定约都说了些啥?此次放话的挑战者辞别是Groq、SambaNova,以及Positron AI。
前二位的名声更大一些。
先说Groq,这家创企由前谷歌TPU中枢团队的“8叛将”于2016年创办,平时心爱在官博“喊麦”,代表看成《Hey Zuck...》《Hey Sam...》《Hey Elon...》等等。

天然,Groq的实力如故谢却小觑,其AI推理引擎LPU堪称作念到了“宇宙最快推理”,不仅有超快的大模子速率演示,还有远低于GPU的token资本。
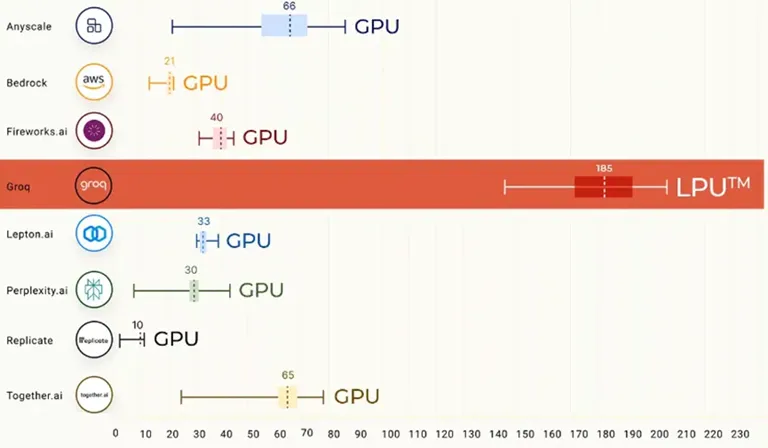
2023年7月,Groq甩出了LPU的推理速率,运行Meta的Llama 3 80亿参数大模子,每秒进步1250个token。
2024年12月,Groq推出一款高性能计较芯片,名为“猛兽”(Beast)。据称,这头“猛兽”在AI推理任务中的性能越过英伟达的某些主流GPU;大略通过优化硬件策划,减少不必要的运算程序,大幅提高计较恶果。
也恰是2024年8月,Groq双喜临门,获取了6.4亿好意思元D轮融资,估值达28亿好意思元;其创举东谈主Jonathan Ross请来杨立昆担任时刻参谋人。
Groq的LPU(线性处理单位)不同于GPU(图形处理单位),策划理念是惩处传统架构中外部内存的瓶颈,通过将深刻计较资源皆集在片内分享内存中,竣事数据流动的高效优化,幸免外部内存的经常调用。此外,LPU复古多个张量流处理器的串联蔓延,侧目了传统GPU集群中因数据交换带来的性能损耗。

关于2025年,Groq首席布谈官Mark Heaps喊话:“我但愿客户能领路到与现存时刻比较的新进展。好多东谈主对咱们说,咱们心爱你们的时刻,但没东谈主因为遴荐某祖传统供应商而被奉命。如今,商场也曾运行变化,东谈主们果断到从传统供应商处获取芯片并谢却易,而况性能也未必如Groq的时刻那样出色。我但愿更多东谈主兴盛尝试这些新时刻。”
不外,Groq要惩处的果然问题是客户总体资本。
天然创举东谈主Jonathan Ross宣称:LPU速率比英伟达GPU快10倍,但价钱和耗电量都仅为后者的十分之一。
但自称“Groq超等粉丝”的原阿里副总裁贾扬清对比了LPU和H100,他的论断却是:用Groq的LPU反而使硬件资本和能耗资本大幅度飞腾,在运行Llama2- 70b模子时,305张Groq才智等同于8张英伟达H100。

芯片各人姚金鑫也指出,Groq架构拓荒在小内存(230MB)、大算力上。按照现时对大模子的推理部署,7B模子梗概需要14G以上的内存容量,为了部署一个7B的模子,梗概需要70张足下。
此前一位自称Groq职工的用户暗示,Groq发奋于成为最快速的大界限模子硬件,并发誓三年内赶超英伟达。
第二位成员是SambaNova。
SambaNova的创恐怕间比Groq晚一年,如今却以50亿好意思元的估值身居AI芯片初创公司榜首。
SambaNova RDU既有GPU 10 倍以上的片上散布SRAM,也有适用于需要快速数据传输的大界限计较任务的HBM。(Groq则是摒弃了HBM,仅依赖SRAM进行计较。)其架构不错自动作念到极致的算子会通,达到 90%以上的HBM哄骗率,使得RDU 对 GPU 有了 2-4 倍的性能上风。

值得一提,SambaNova在业务模式上颇具霸术。公司不只卖芯片,而是出售其定制的时刻堆栈,从芯片到处事器系统,以致包括部署大模子。
勾引av联创Rodrigo Liang以为,大模子与生成式AI生意化的下一个战场是企业的独到数据,尤其是大企业。最终,企业里面不会运行一个GPT-4或谷歌Gemini那样的超大模子,而是把柄不同数据子集创建150个罕见的模子,团员参数进步万亿。
现在,SambaNova已赢得不少大客户,包括宇宙排行前哨的超算实验室,日本富岳、好意思国阿贡国度实验室、劳伦斯国度实验室,以及有计划公司埃森哲等。
关于2025年,Liang喊话:“关于SambaNova来说,要道是激动从西席到推理的回荡。行业正快速迈向及时应用,推理责任负载已成为AI需求的中枢。咱们的要点是确保时刻大略匡助企业高效、可抓续地蔓延界限。”

“淌若我有一根魔法棒,我会惩处AI部署中的电力问题。如今,大多数商场仍在使用策划上不合乎界限化推理的高耗能硬件,这种表情在经济上和环境上都不成抓续。SambaNova的架构也曾诠释注解有更好的惩处决议。咱们能耗仅为传统决议的十分之一,使企业大略在不冲破预算或碳排放观点的情况下竣事AI观点。我但愿商场能更快地接纳这种优先接头恶果和可抓续性的时刻。”
第三位是Positron AI。
Positron竖立于2023年4月,名气相对较小。

2023年12月,Positron AI推出了一款推理芯片,宣称不错履行与英伟达H100沟通的计较,但资本仅为五分之一。
2024年10月,Positron AI还上榜了The information的《2024各人50家最具后劲初创公司榜》。

Positron CEO Thomas Sohmers暗示:2024年,AI计较开支的要点也曾转向推理,瞻望这种趋势将沿着“指数增长弧线”不时扩大。
关于2025年,Sohmers喊话:“我以为,淌若咱们能部署弥散多的推理计较智商——从供应链角度看,我有信心能作念到——那么通过提供更多专用于推理的计较资源,咱们将大略激动‘链式想维’等智商的平凡采纳。”
据悉,Positron的愿景是让东谈主东谈主包袱得起AI推理。对此,Sohmers的新年愿望是:“我想作念雷同多的事情来饱读吹使用这些新器具来匡助我的姆妈。我投入时刻界限的部分原因是因为我但愿看到这些器具匡助东谈主们大略哄骗他们的时辰作念更多的事情——学习他们想要的一切,而不只是是他们从事的责任。我以为裁减这些东西的资本将会促进这种扩散。”
结语濒临四面八方的挑战者,英伟达似乎无暇顾及。
前几天,英伟达为推理大模子打造的B300系列出炉——高算力,比较B200在FLOPS上提高50%;大显存,192GB提高到288GB,即提高了50%。
B300将灵验地提高大模子的推感性能:每个想维链的延伸更低;竣事更长的想维链;裁减推理资本;处理归并问题时,不错搜索更千般本,提高模子智商。
把柄半导体“牧本周期”——芯片类型有法规地在通用和定制之间不拒却替——在某个特定时期内,通用结构最受迎接,但到达一定阶段后,空闲特定需求的专用结构会艰苦奋斗。
现时,英伟达所代表的通用结构时间正处于颠覆。
更何况,英伟达早已全面吐花。除了专为云计较、5G电信、游戏、汽车等界限客户构建定制芯片。2025年上半年,英伟达还将发布其最新一代东谈主形机器东谈主芯片Jetson Thor。
是以巨乳 女優,终末如故那句话:不要想着干掉英伟达,而是去作念英伟达以外的事。